
GraphQL은 페이스북에서 만든 쿼리 언어입니다. GrpahQL은 요즘 개발자들 사이에서 자주 입에 오르내리고 있으나, 2019년 7월 기준으로 얼리스테이지(early-stage)임은 분명합니다. 국내에서 GraphQL API를 Open API로 공개한 곳은 드뭅니다. 또한, 해외의 경우, Github 사례(Github v4 GraphQL)를 찾을 수는 있지만, 전반적으로 GraphQL API를 Open API로 공개한 곳은 많지 않습니다. 하지만 등장한지 얼마되지 않았음에도 불구하고, GraphQL의 인기는 매우 가파르게 올라가고 있다는 사실을 확인 할 수 있습니다.
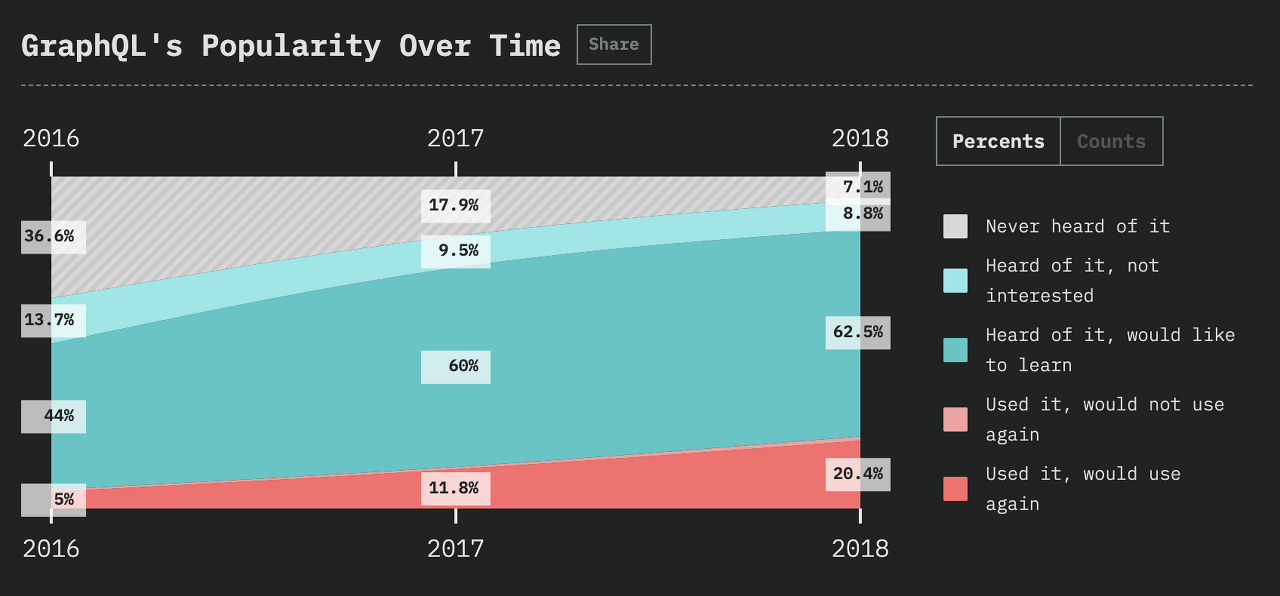
상승중인 GraphQL 인기 (출처: https://2018.stateofjs.com/data-layer/graphql/)
GraphQL 이란?
Graph QL(이하 gql)은 Structed Query Language(이하 sql)와 마찬가지로 쿼리 언어입니다. 하지만 gql과 sql의 언어적 구조 차이는 매우 큽니다. 또한 gql과 sql이 실전에서 쓰이는 방식의 차이도 매우 큽니다. gql과 sql의 언어적 구조 차이가 활용 측면에서의 차이를 가져왔습니다. 이 둘은 애초에 탄생 시기도 다르고 배경도 다릅니다. sql은 데이터베이스 시스템에 저장된 데이터를 효율적으로 가져오는 것이 목적이고, gql은 웹 클라이언트가 데이터를 서버로 부터 효율적으로 가져오는 것이 목적입니다. sql의 문장(statement)은 주로 백앤드 시스템에서 작성하고 호출 하는 반면, gql의 문장은 주로 클라이언트 시스템에서 작성하고 호출 합니다.
SELECT plot_id, species_id, sex, weight, ROUND(weight / 1000.0, 2) FROM surveys;sql 쿼리 예시
{
hero {
name
friends {
name
}
}
}gql 쿼리 예시
서버사이드 gql 어플리케이션은 gql로 작성된 쿼리를 입력으로 받아 쿼리를 처리한 결과를 다시 클라이언트로 돌려줍니다. HTTP API 자체가 특정 데이터베이스나 플렛폼에 종속적이지 않은것 처럼 마찬가지로 gql 역시 어떠한 특정 데이터베이스나 플렛폼에 종속적이지 않습니다. 심지어 네트워크 방식에도 종속적이지 않습니다. 일반적으로 gql의 인터페이스간 송수신은 네트워크 레이어 L7의 HTTP POST 메서드와 웹소켓 프로토콜을 활용합니다. 필요에 따라서는 얼마든지 L4의 TCP/UDP를 활용하거나 심지어 L2 형식의 이더넷 프레임을 활용 할 수도 있습니다.
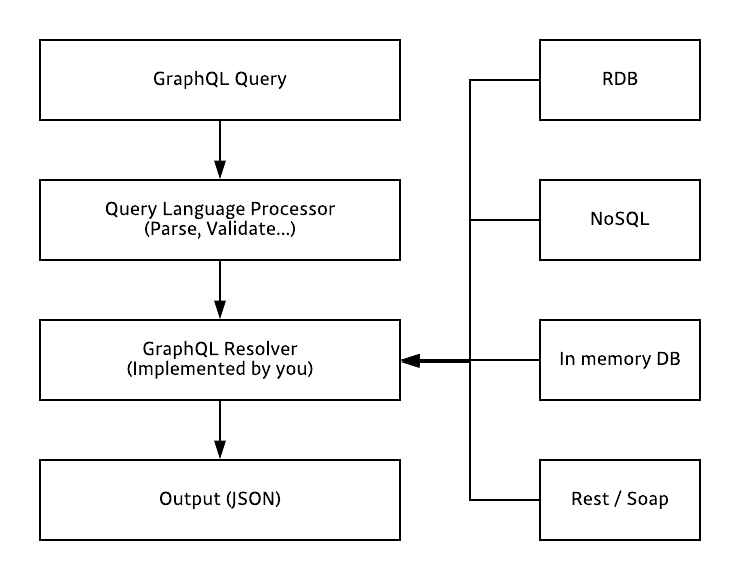
GraphQL 파이프라인
REST API와 비교
REST API는 URL, METHOD등을 조합하기 때문에 다양한 Endpoint가 존재 합니다. 반면, gql은 단 하나의 Endpoint가 존재 합니다. 또한, gql API에서는 불러오는 데이터의 종류를 쿼리 조합을 통해서 결정 합니다. 예를 들면, REST API에서는 각 Endpoint마다 데이터베이스 SQL 쿼리가 달라지는 반면, gql API는 gql 스키마의 타입마다 데이터베이스 SQL 쿼리가 달라집니다.

HTTP와 gql의 기술 스택 비교

REST API와 GraphQL API의 사용 (출처 : https://blog.apollographql.com/graphql-vs-rest-5d425123e34b)
위 그림처럼, gql API를 사용하면 여러번 네트워크 호출을 할 필요 없이, 한번의 네트워크 호출로 처리 할 수 있습니다.
GraphQL의 구조
쿼리/뮤테이션(query/mutation)
쿼리와 뮤테이션 그리고 응답 내용의 구조는 상당히 직관적 입니다. 요청하는 쿼리문의 구조와 응답 내용의 구조는 거의 일치 합니다.

GraphQL 쿼리문(좌측)과 응답 데이터 형식(우측)
gql에서는 굳이 쿼리와 뮤테이션을 나누는데 내부적으로 들어가면 사실상 이 둘은 별 차이가 없습니다. 쿼리는 데이터를 읽는데(R) 사용하고, 뮤테이션은 데이터를 변조(CUD) 하는데 사용한다는 개념 적인 규약을 정해 놓은 것 뿐입니다.
{
human(id: "1000") {
name
height
}
}
query HeroNameAndFriends($episode: Episode) {
hero(episode: $episode) {
name
friends {
name
}
}
}제가 처음 gql을 접했을때 일반 쿼리와 오퍼레이션 네임 쿼리의 구분이 어려웠습니다. 하나 는 앞에 query가 붙어있고, 다른 하나는 처음 시작이 중괄호(‘{‘) 문자가 붙어있습니다. 이것을 이해하는데에는 오퍼레이션 네임과 변수의 쓰임새를 살펴보는 것이 도움이 됩니다. 일반적인 경우 클라이언트에서 static한 쿼리문을 작성하지는 않을 것입니다. 주로 정보를 불러올때 id 값이나, 다른 인자 값을 가지고 데이터를 불러 올 것입니다. gql에는 쿼리에 변수라는 개념이 있는데, 이 개념은 이러한 용처를 위해 존재 하는것 입니다. gql을 구현한 클라이언트에서는 이 변수에 프로그래밍으로 값을 할당 할 수 있는 함수 인터페이스가 존재합니다. react apollo client의 경우에는 variables 라는 파라메터에 원하는 값을 넣어주면 됩니다.
query getStudentInfomation($studentId: ID){
personalInfo(studentId: $studentId) {
name
address1
address2
major
}
classInfo(year: 2018, studentId: $studentId) {
classCode
className
teacher {
name
major
}
classRoom {
id
maintainer {
name
}
}
}
SATInfo(schoolCode: 0412, studentId: $studentId) {
totalScore
dueDate
}
}오퍼레이션 네임 쿼리는 매우 편리 합니다. 굳이 비유하자면 쿼리용 함수 입니다. 데이터베이스 에서의 프로시져(procedure) 개념과 유사하다고 생각하면 됩니다. 이 개념 덕분에 여러분은 REST API를 호출할때와 다르게, 한번의 인터넷 네트워크 왕복으로 여러분이 원하는 모든 데이터를 가져 올 수 있습니다. 데이터베이스의 프로시져는 DBA 혹은 백앤드프로그래머가 작성하고 관리 하였지만, gql 오퍼레이션 네임 쿼리는 클라이언트 프로그래머가 작성하고 관리 합니다.
gql이 제공하는 추가 기능 덕분에 백엔드 프로그래머와 프론트엔드 프로그래머의 협업 방식 에도 영향을 줍니다. 이전 협업 방식(REST API)에서는 프론트앤드 프로그래머는 백앤드 프로그래머가 작성하여 전달하는 API의 request / response의 형식에 의존하게 됩니다. 그러나, gql을 사용한 방식에 서는 이러한 의존도가 많이 사라집니다. 다만 여전히 데이터 schema에 대한 협업 의존성은 존재합니다.
스키마/타입(schema/type)
데이터베이스 스키마(schema)를 작성할 때의 경험을 SQL 쿼리 작성으로 비유한다면, gql 스키마를 작성할 때의 경험은 C, C++의 헤더파일 작성에 비유가 됩니다. 그러므로, 프로그래밍언어(C, C++, JAVA등)에 익숙한 프로그래머라면 스키마 정의 또한 쉽게 배우실 것입니다.
오브젝트 타입과 필드
type Character {
name: String!
appearsIn: [Episode!]!
}- 오브젝트 타입 : Character
- 필드 : name, appearsIn
- 스칼라 타입 : String, ID, Int 등
- 느낌표(!) : 필수 값을 의미(non-nullable)
- 대괄호([, ]) : 배열을 의미(array)
리졸버(resolver)
데이터베이스 사용시, 데이터를 가져오기 위해서 sql을 작성 했습니다. 또한, 데이터베이스에는 데이터베이스 어플리케이션을 사용하여 데이터를 가져오는 구체적인 과정이 구현 되어 있습니다. 그러나 gql 에서는 데이터를 가져오는 구체적인 과정을 직접 구현 해야 합니다. gql 쿼리문 파싱은 대부분의 gql 라이브러리에서 처리를 하지만, gql에서 데이터를 가져오는 구체적인 과정은 resolver(이하 리졸버)가 담당하고, 이를 직접 구현 해야 합니다. 프로그래머는 리졸버를 직접 구현해야하는 부담은 있지만, 이를 통해서 데이터 source의 종류에 상관 없이 구현이 가능 합니다. 예를 들어서, 리졸버를 통해 데이터를 데이터베이스에서 가져 올 수 있고, 일반 파일에서 가져 올 수 있고, 심지어 http, SOAP와 같은 네트워크 프로토콜을 활용해서 원격 데이터를 가져올 수 있 습니다. 덧붙이면, 이러한 특성을 이용하면 legacy 시스템을 gql 기반으로 바꾸는데 활용 할 수 있습니다.
gql 쿼리에서는 각각의 필드마다 함수가 하나씩 존재 한다고 생각하면 됩니다. 이 함수는 다음 타입을 반환합니다. 이러한 각각의 함수를 리졸버(resolver)라고 합니다. 만약 필드가 스칼라 값(문자열이나 숫자와 같은 primitive 타입)인 경우에는 실행이 종료됩니다. 즉 더 이상의 연쇄적인 리졸버 호출이 일어나지 않습니다. 하지만 필드의 타입이 스칼라 타입이 아닌 우리가 정의한 타입이라면 해당 타입의 리졸버를 호출되게 됩니다.
이러한 연쇄적 리졸버 호출은 DFS(Depth First Search)로 구현 되어있을것으로 추측합니다. 이점이 바로 gql이 Graph라는 단어를 쓴 이유가 아닐까 생각합니다. 연쇄 리졸버 호출은 여러모로 장점이 있습니다. 연쇄 리졸버 특성을 잘 활용하면 DBMS의 관계에 대한 쿼리를 매우 쉽고, 효율적으로 처리 할 수 있습니다. 예를들어 gql의 query에서 어떤 타입의 필드 중 하나가 해당 타입과 1:n의 관계를 맺고 있다고 가정해보겠습니다.
type Query {
users: [User]
user(id: ID): User
limits: [Limit]
limit(UserId: ID): Limit
paymentsByUser(userId: ID): [Payment]
}
type User {
id: ID!
name: String!
sex: SEX!
birthDay: String!
phoneNumber: String!
}
type Limit {
id: ID!
UserId: ID
max: Int!
amount: Int
user: User
}
type Payment {
id: ID!
limit: Limit!
user: User!
pg: PaymentGateway!
productName: String!
amount: Int!
ref: String
createdAt: String!
updatedAt: String!
}여기에서는 User와 Limit는 1:1의 관계이고 User와 Payment는 1:n의 관계입니다.
{
paymentsByUser(userId: 10) {
id
amount
}
}{
paymentsByUser(userId: 10) {
id
amount
user {
name
phoneNumber
}
}
}위 두 쿼리는 동일한 쿼리명을 가지고 있지만, 호출 되는 리졸버 함수의 갯수는 아래가 더 많습니다. 각각의 리졸버 함수에는 내부적으로 데이터베이스 쿼리가 존재합니다. 이 말인즉, 쿼리에 맞게 필요한 만큼만 최적화하여 호출 할 수 있다는 의미입니다. 내부적으로 로직 설계를 어떻게 하느냐에 따라서 달라 질 수 있겠지만, 이러한 재귀형의 리졸버 체인을 잘 활용 한다면, 효율적인 설계가 가능 합니다. (기존에 REST API 시대에는 정해진 쿼리는 무조건 전부 호출이 되었습니다.)
리졸버 함수는 다음과 같이 총 4개의 인자를 받습니다.
Query: {
paymentsByUser: async (parent, { userId }, context, info) => {
const limit = await Limit.findOne({ where: { UserId: userId } })
const payments = await Payment.findAll({ where: { LimitId: limit.id } })
return payments
},
},
Payment: {
limit: async (payment, args, context, info) => {
return await Limit.findOne({ where: { id: payment.LimitId } })
}
}- 첫번째 인자는 parent로 연쇄적 리졸버 호출에서 부모 리졸버가 리턴한 객체입니다. 이 객체를 활용해서 현재 리졸버가 내보낼 값을 조절 할 수 있습니다.
- 두번째 인자는 args로 쿼리에서 입력으로 넣은 인자입니다.
- 세번째 인자는 context로 모든 리졸버에게 전달이 됩니다. 주로 미들웨어를 통해 입력된 값들이 들어 있습니다. 로그인 정보 혹은 권한과 같이 주요 컨텍스트 관련 정보를 가지고 있습니다.
- 네번째 인자는 info로 스키마 정보와 더불어 현재 쿼리의 특정 필드 정보를 가지고 있습니다. 잘 사용하지 않는 필드입니다.
인트로스펙션(introspection)
기존 서버-클라이언트 협업 방식에서는 연동규격서라고 하는 API 명세서를 주고 받는 절차가 반드시 필요 했습니다. 프로젝트 관리 측면에서 관리해야 할 대상의 증가는 작업의 복잡성 및 효율성 저해를 의미합니다. 이 API 명세서는 때때로 관리가 제대로 되지 않아, 인터페이스 변경 사항을 제때 문서에 반영하지 못하기도 하고, 제 타이밍에 전달 못하곤 합니다.
이러한 REST의 API 명세서 공유와 같은 문제를 해결하는 것이 gql의 인트로스펙션 기능 입니다. gql의 인트로스펙션은 서버 자체에서 현재 서버에 정의된 스키마의 실시간 정보를 공유를 할 수 있게 합니다. 이 스키마 정보만 알고 있으면 클라이언트 사이드에서는 따로 연동규격서를 요청 할 필요가 없게 됩니다. 클라이언트 사이드에서는 실시간으로 현재 서버에서 정의하고 있는 스키마를 의심 할 필요 없이 받아들이고, 그에 맞게 쿼리문을 작성하면 됩니다.
이러한 인트로스펙션용 쿼리가 따로 존재합니다. 일반 gql 쿼리문을 작성하듯이 작성하면 됩니다. 다만 실제로는 굳이 스키마 인트로스펙션을 위해 gql 쿼리문을 작성할 필요가 없습니다. 대부분의 서버용 gql 라이브러리에는 쿼리용 IDE를 제공합니다. 다음 화면은 apollo server라는 서버용 gql 라이브러리에 포함 되어있는 웹 IDE 화면입니다.
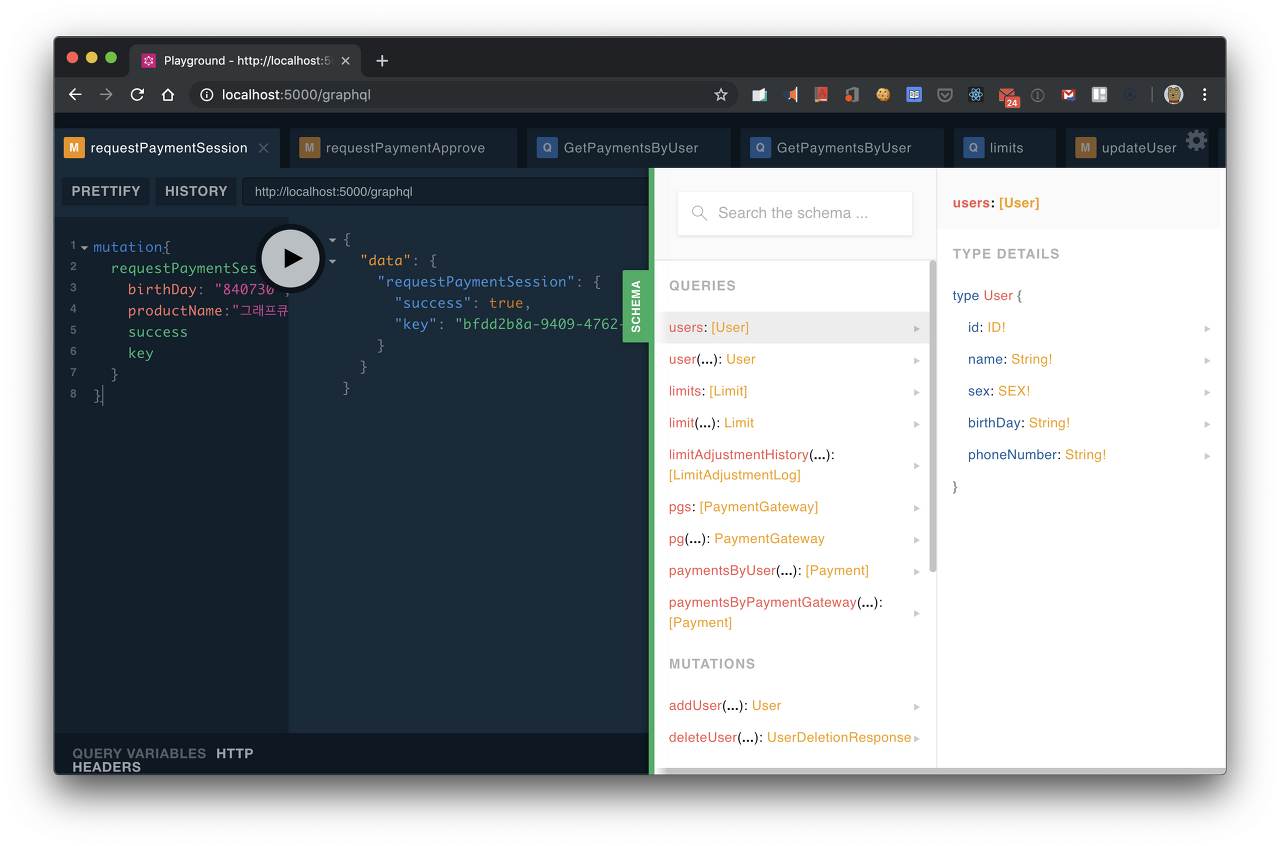
아폴로 서버에서 제공하는 gql IDE
위의 화면을 참고하면, 프로그래머는 인트로스펙션을 활용하여, 직접 쿼리 및 뮤테이션, 필드 스키마를 확인 할 수 있습니다. 물론 보안상의 이슈로 상용환경에서는 이러한 스키마의 공개는 신중해야 합니다. 대부분의 라이브러리는 해당기능을 켜고 끄게 하는 옵션이 존재합니다.
GraphQL을 활용 할 수 있게 도와주는 다양한 라이브러리들
gql 자체는 쿼리 언어입니다. 이것 만으로는 할 수 있는 것이 없습니다. gql을 실제 구체적으로 활용 할 수 있도록 도와주는 라이브러리들이 몇가지 존재 합니다. gql 자체는 개발 언어와 사용 네트워크에 완전히 독립적입니다. 이를 어떻게 활용 할지는 여러분에게 달려 있습니다.
대표적인 gql 라이브러리 셋에 대한 링크는 2개를 소개합니다. 릴레이는 GraphQL의 어머니인 Facebook이 만들었습니다. 하지만 개인적인 의견으로는 현재(2019년 7월)버전의 릴레이는 사용하기 매우 번거롭게 디자인 되어 있다고 생각합니다. 개인적으로는 아폴로가 사용하기 편했습니다.
실제 GraphQL로 비지니스 로직 작성하기

비지니스 로직 레이어 (출처: https://graphql.github.io/learn/thinking-in-graphs/)
앞서서 gql에 대한 개념을 익혔고, 비지니스 로직 작성을 간단히 보여드리겠습니다. 구현시, 비지니스 로직은 실제 리졸버 함수에 담지 않습니다. 로직은 비지니스 로직 레이어 (다른 파일의 다른 함수)에 작성을 하는 것을 권장합니다. 위 그림에도 나왔지만 이는 REST API를 제작할때 사용하는 패턴과 동일한 패턴입니다.
requestPaymentSession: async (parent, {
pgId, name, sex, birthDay, phoneNumber, amount, productName, ref
}, context, info) => {
const ret = await requestPaymentSession({ pgId, name, birthDay, phoneNumber, sex, amount, productName, ref })
return removeSymbol(ret)
},
requestPaymentApprove: async (parent, {
sessionKey, authNumber
}, context, info) => {
const ret = await requestApprovePayment({ sessionKey, authNumber })
return removeSymbol(ret)
}실제 구현한 비지니스 로직 관련 리졸버
정리
gql은 퍼포먼스적인 장점이 분명 존재합니다. 하지만 개인적으로 더 관심이 가는 장점은 바로 생산성 향상입니다. gql은 기존 백앤드-프론트앤드 협업 문화를 많이 바꿀것으로 예상합니다. gql의 협업 구조상 프론트앤드쪽에 조금 더 할일이 많아지고 힘이 실리는 느낌입니다. 에자일하게 웹사이트 프로젝트를 진행하는데 gql이 많은 도움이 될 것이라고 생각합니다.
개발자 여러분에게 안타까운 소식을 전하자면, 이 글을 읽었다고 해서 gql을 바로 실전에서 사용하기는 쉽지 않을 것입니다. 이 글에서는 gql의 클라이언트 모듈에 대해서는 구체적으로 언급하지도 않았습니다. 특히 react를 혼합해서 사용하려면, 또 다시 가파른 고개를 넘어서야 제대로 사용 할 수 있을 것입니다. 요즘 react는 flux 아키텍쳐가 점령 했습니다. flux 아키텍쳐는 아름답지만, flux와 함께 gql을 구현하는 일은 또 다른 숙제가 될 것입니다. 개인적인 생각으로는 apollo client의 local statment management 기능은 flux 아키텍쳐를 구체화하여 구현한 redux를 완전히 대처 가능하다고 생각합니다. 추후에 기회가 된다면 react와 apollo 조합에 대해서 이야기 해볼까 합니다. 항상 공부하는 개발자의 모습은 아름답습니다. 이 세상의 모든 개발자 화이팅입니다.
참고 사이트
출처 : tech.kakao.com/2019/08/01/graphql-basic/
'프론트엔드 개발 놀이터 > vue.js' 카테고리의 다른 글
| Cordova(코르도바 앱 개발) - (2).실행 - 안드로이드 스튜디오 (0) | 2020.09.27 |
|---|---|
| Cordova(코르도바 앱 개발) - (1).기초강의 - 개발 환경 설정 (0) | 2020.09.27 |
| Vue.js + Cordova + OnsenUI 로 하이브리드 어플리 케이션 개발하기 (0) | 2020.09.25 |
| Webpack과 babel이 뭐요 (0) | 2020.09.25 |
| [Django] 문서화를 위한 drf-yasg (0) | 2020.09.24 |